0x00 idapython 调试
配置好IDA 7.5 免安装版之后,可以正常使用idapython,但是在import idc会报错。修改%IDA_7.5%\python\3\ida_idaapi.py文件,在第80行,添加如下:

在vscode添加插件idacode

在IDA pro 安装插件,在https://github.com/ioncodes/idacode/releases处下载。解压到%IDAPATH%/plugins中。
编辑 idacode_utils/settings.py,把 Python 的可执行文件路径改为自己电脑上 Python 的路径

重新打开,在输出窗口就能看到是否成功,可能会提示缺少模块,可以通过Pip安装模块debugpy

安装成功就是这样的。

0x01 idapython 函数
0x02 pclntab及如何定位pclntab
pclntab 全称为 Program Counter Line Table(程序计数器行数映射表)。对应汇编中,可以简单的理解为EIP。其结构体定义如下:
对于我们来说比较重要的主要是函数名称表和原文件表,我将其简单划分成了三个部分,分别是pclntab_header,func_tbl_entry,srcfile_tbl_entry:
- pclntab_header:这是pclntab的头部,包含pclntab的幻字,架构,以及字节宽度
- func_tbl:存储了函数个数,以及函数的地址,函数的Function Struct结构的偏移组成的一个list
- src_tbl:存储了src_file的个数,以及指向src_file字符串的地址的偏移123456789101112131415161718192021222324252627type pclntab struct{type pclntab_header struct{//sizeof(pclntab_header) == 8DWORD Magic_Number //+0x00 幻字WORD Unknow //+0x04 暂无他用BYTE min_lc //+0x06 instruction size quantum -->1 为 x86, 4 为 ARMBYTE ptr_sz //+0x07 size of uintptr --->32bit 的为 4,64 bit 的为 8}type func_tbl struct{DWORD NumOfFunc //+0x08 number of functionDWORD func_addr1 //+0x0B address of function1DWORD offset_of_funcstruct1 //+0x0F offset of func structDWORD func_addr2 //+0x0B address of function1DWORD offset_of_funcstruct2 //+0x0F offset of func struct............}type srcfile_tbl struct{DWORD NumOfScrFileDWORD offset_of_srcfile1 //+0x(sizeof(func_tbl)+ ptr_sz)..............}}
pclntab_header结构是定位pclntab的关键,因为pclntab_header存在MagicNumber为0xFFFFFFFB,所以只需要在文件中遍历0xFFFFFFFB,以及确定min_lc或者ptr_sz值的有效性即可。
func_tbl除了NumOfFunc,剩下就是func_addr和offset_of_funcstruct1组成的一个list,而offset_of_funcstruct只是一个指向funcstruct的一个偏移。funcstruct真正的地址是pclntable的地址加上func_struct的偏移,同理,srcfile_tbl除了NumOfScrFile,也包含一个存储srcfilename偏移的list。同样的,指向srcfilename地址也是pclntable的地址加上srcfilename的偏移。
pclntab的地址是0x004CBA00,而第一个函数的funcstruct的偏移为0x387C,所以funcstruct的地址为pclntb_addr + func_struct_offset,即0x004CF27C。func_struct的结构如下.其中比较重要的是func_entry以及offset_funcname:
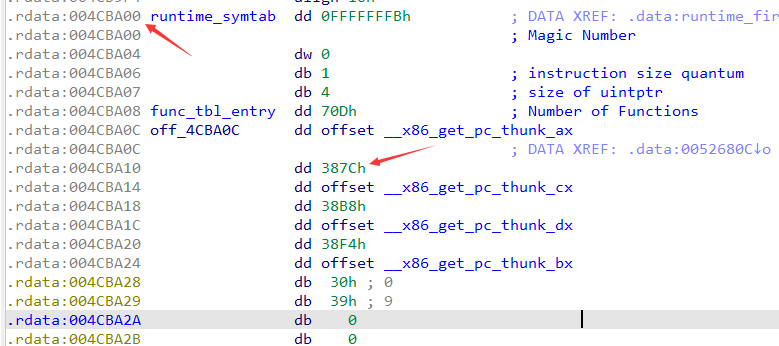
offset_funcname是函数名称的偏移量,和func_struct一样,addr_funcname 是通过pclntab的地址加上offset_funcname的值得来,即
0x03 Moduledata及如何定位 First_Moduledata
Module 中可以包含多个不同的 Package,而每个 Package 中可以包含多个目录和很多的源码文件。Moduledata结构如下:
显然可以看到,moduledata之间通过链表的形式进行链接,而在Go文件中,只有firstmoduledata才拥有完整的结构,其中,比较重要的结构主要是
由此看来,针对Go逆向,首先就是需要寻找firstmoduledata,因为他包含了主要可以使用的信息,functble srcfiletble typelink等等。很显然,firstmoduledata第一个成员就是pclntable,只要定位到了pclntable就可以定位到firstmoduledata。
0x04 Type介绍与解析
Go存在多种数据类型,有以bool,int等为代表的Basic Type(基本数据类型),和以array,slice等为代表的复杂数据类型。而这些数据类型都是以一个名为rtype为基础的结构体拓展而来。如果是一些包括bool在内的简单数据类型,rtype就可以简单概括,如果是一些复杂的数据类型,则需要在rtype的基础上进行拓展而来。

上节,在介绍firstmoduledata结构的时候,存在firstmoduledata.typelinks成员以及firstmoduledata.typenumber成员,typelinks是一个存储着type的offset的list,而type_addr是firstmoduledata.typeaddr加上这些偏移所得到的。typenumber则表征着有多少个type。


0x04-1 rtype 解析
rtype表征一个简单的数据结构,其他类型都是从其拓展而来。rtype结构如下:
其中比较重要的结构如下:
- kind:表示变量的类型,其与KIND_MASK进行按位与操作得到的值才可以表示变量的类型,而KIND_MASK = (1 << 5) - 11type_kind = kind & ((1 << 5) - 1)
type_kind其实作为一个枚举类型存在,比如type_kind 为36,则表示是一个Ptr类型。
- str:表示指向变量名的offset:offset加上typeaddr的地址就是typename的地址
|
|
值得注意的是,type name并不是一个单纯的string类型,而是是一个type_name 结构体
0x04-2 Ptr 解析
因为rtype.kind表征着type的类型,所以,在解析完rtype,判断一下kind,然后在去解析对应的复杂变量结构体即可。
之前说过复杂数据类型都是从rtype拓展而来,ptrType结构如下,所以当解析到kind为Ptr的时候,读取当前rtype+0x20处的数据,进行解析就是下一个rtype【图7】
|
|

0x04-3 Struct 解析
structType如下,只需要依次解析位于偏移0x20的pkgPath和偏移位于0x24的fields两个成员即可。
0x05 String类型遍历和解析
String暂时只解析常量string和字符串变量。
0x05-1 const string 解析
const 主要是通过代码匹配实现的。如下所示,const string 在进行使用的时候,都会将字符串长度传入栈中,只需要暴力匹配即可。另外go_parser的这部分是从 golang_loader_assist 移植而来,但是缺少了一个寄存器,导致部分string匹配不上。
0x05-1 ptr string 解析
go_parser关于ptr 解析好像也是暴力匹配,但是J!4Yu师傅提出利用string交叉引用来解析ptrstring的方法。
在解析type的时候暂时存了stringtype_addr的地址,然后进行交叉引用,找到所有的引用。然后判断下面四个条件即可:
因为name为string的其实有很多,或者kind为String的其实也有很多,所以当确定name带有String,且kind为string时,便是符合条件的type结构体。【图9】
